Fri, 04 Mar 2011 17:34:19 GMT
Netcat is a pretty nice piece of software. Because of its simplicity, it is very versatile. For sending a single file inside the local network, I can just use
cat somefile.file | netcat -l -p 13337 -q 0
on the server side and then
netcat server 13337 -q 0 > somefile.file
on the client side. If I do not want to remember the filename, or if I want to send directories, I can use
tar -cf - Directory/ | netcat -l -p 13337 -q 0
and on the other side
netcat server 13337 -q 0 | tar -xf -
For noobs who cannot use netcat, Wikipedia has a nice example of serving a single file which is downloadable via a webbrowser
There are options for using UDP instead of TCP. But something that would be very desirable is a possibility to use STUN to create a p2p-connection. I do not think that netcat already has this possibility, but I am quite sure that something like that exists. Say, I give some Stun-Server, and the Program then passes some credentials to its stderr which I can then send (myself) to the receiver, which also passes them and creates a connection via UDP, and a bidirectional stream then. Since netcat is so good because of its simplicity, such a "Stun Netcat" would be very nice for sending files, too.
One could even add a simple GUI, such that n00bs can use it. If something like that exists, please tell me.
Update: Notice that I forgot to mention that "netcat" is called "nc" in some implementations, and "-q 0" is called "-c" (or completely different), depending on the implementation of netcat you have. Read the documentation for your implementation, in case of doubt.
cat somefile.file | netcat -l -p 13337 -q 0
on the server side and then
netcat server 13337 -q 0 > somefile.file
on the client side. If I do not want to remember the filename, or if I want to send directories, I can use
tar -cf - Directory/ | netcat -l -p 13337 -q 0
and on the other side
netcat server 13337 -q 0 | tar -xf -
For noobs who cannot use netcat, Wikipedia has a nice example of serving a single file which is downloadable via a webbrowser
{ echo -ne "HTTP/1.0 200 OK\r\n\r\n"; cat some.file; } | nc -l 8080There are options for using UDP instead of TCP. But something that would be very desirable is a possibility to use STUN to create a p2p-connection. I do not think that netcat already has this possibility, but I am quite sure that something like that exists. Say, I give some Stun-Server, and the Program then passes some credentials to its stderr which I can then send (myself) to the receiver, which also passes them and creates a connection via UDP, and a bidirectional stream then. Since netcat is so good because of its simplicity, such a "Stun Netcat" would be very nice for sending files, too.
One could even add a simple GUI, such that n00bs can use it. If something like that exists, please tell me.
Update: Notice that I forgot to mention that "netcat" is called "nc" in some implementations, and "-q 0" is called "-c" (or completely different), depending on the implementation of netcat you have. Read the documentation for your implementation, in case of doubt.
Show comments (Requires JavaScript, loads external content and cookies from Disqus.com)
Thu, 03 Mar 2011 20:55:56 GMT
Yet another old programming environment I used for quite a long time is the Borland C++ Builder. It is the brother of the very famous Borland Delphi, and the IDE and API looks quite similar to it. I was given a book named "C++ für Kids", which taught the basics of it, but seems like already in my younger years I knew I would not like C++.
However, it is a quite nice environment with which one can easily create simple applications.
When starting, one usually sees a simple Window "Form 1". At the left side, several properties can be set, for example, the Caption of that first window.
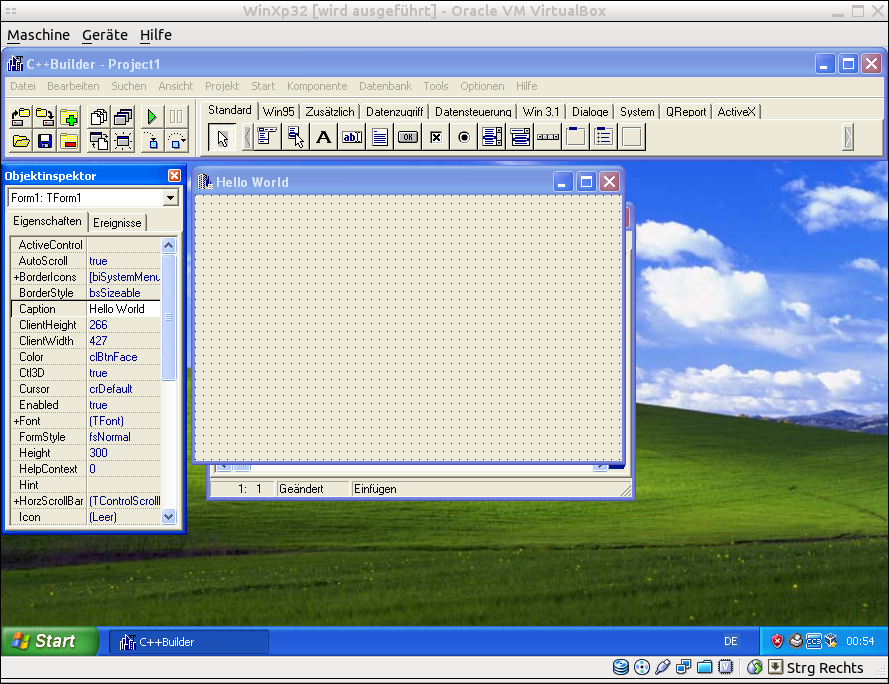
Like in Visual C++, one can put several widgets on that window, and work with them.
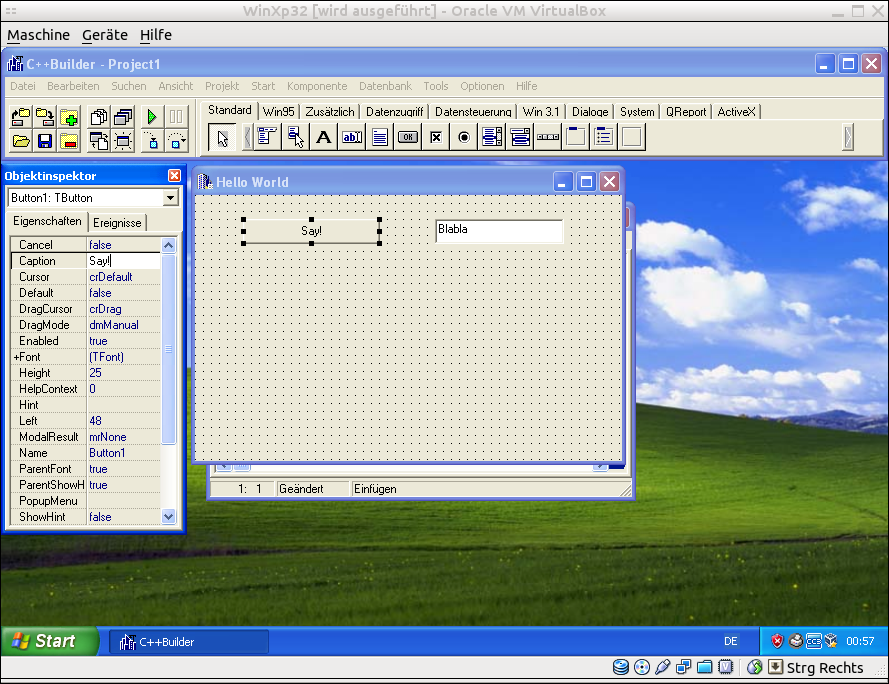
When double-klicking on one of these widgets, the default event-handler is created. For a button, this is the OnClick-handler. It can be set appropriate.
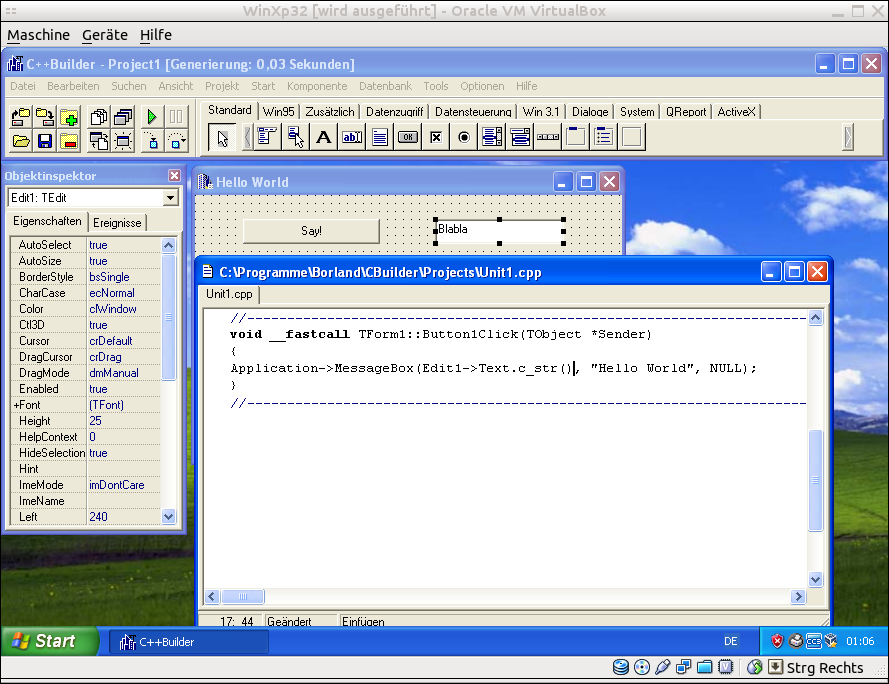
As soon as we are finished with making our application, we can run it!
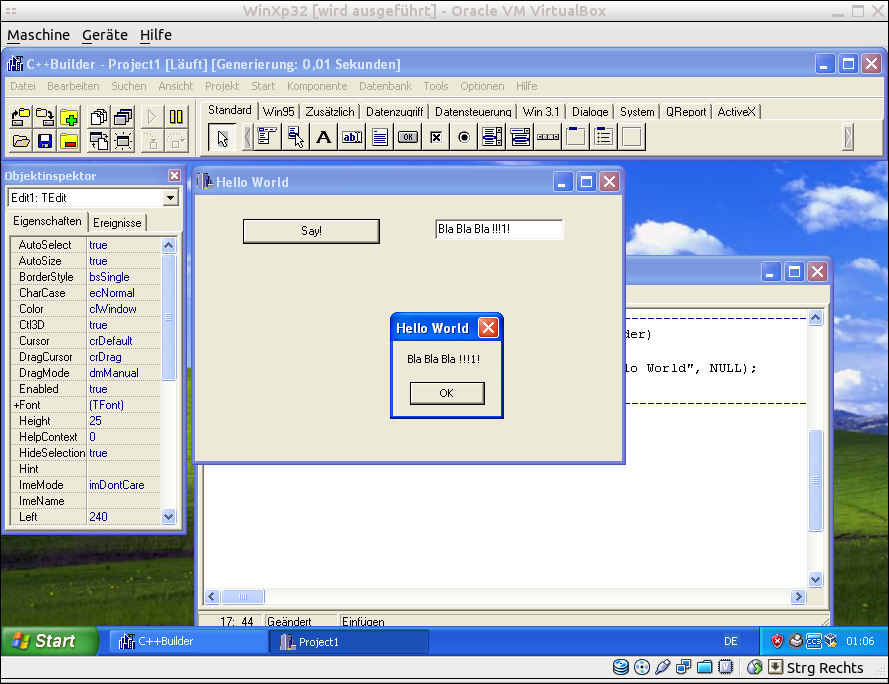
It is as simple as that, and with just a little more efforts, nice applications can be made.
However, it is a quite nice environment with which one can easily create simple applications.
When starting, one usually sees a simple Window "Form 1". At the left side, several properties can be set, for example, the Caption of that first window.
Like in Visual C++, one can put several widgets on that window, and work with them.
When double-klicking on one of these widgets, the default event-handler is created. For a button, this is the OnClick-handler. It can be set appropriate.
As soon as we are finished with making our application, we can run it!
It is as simple as that, and with just a little more efforts, nice applications can be made.
Sat, 26 Feb 2011 01:43:24 GMT
I just played a quite nice point-and-click-adventure, Suspended Sentence. You wake up in a Cryo-Chamber on a space ship that seems to be broken. Everyone else on the ship seems dead, and many parts of the ship are broken, and there is giant broccoli growing everywhere.
The game is of the kind that is sometimes made as projects for applied computer science lectures - if you play it, do not expect too much. But it is well-done, it is nice, and it will keep you playing for about half an hour.
So if you have some time to waste, playing this game is probably not the worst kind of wasting it.
The game is of the kind that is sometimes made as projects for applied computer science lectures - if you play it, do not expect too much. But it is well-done, it is nice, and it will keep you playing for about half an hour.
So if you have some time to waste, playing this game is probably not the worst kind of wasting it.
Thu, 24 Feb 2011 11:28:33 GMT
There are plenty of Webbrowsers out there. From the widely-used "ordinary" ones like Firefox and Google Chrome to less-widely used ordinary ones like Epiphany and Midori and Konqueror to the less-widely used less-ordinary ones like w3m and the several lynx-derivatives. What they have in common is that they are either made for the usual user and supporting most of the modern websites, or made for the old-school unix-fans and therefore not supporting modern websites using ajax etc. - it seems like using a non-mainstream browser is seen as an equivalent to not using mainstream websites.
Well, there are exceptions like some add-ons for Firefox which add Vi-like keybindings. And there is uzbl. Uzbl is not a browser, it is more like a framework for creating browsers and implementing several features. But the Ubuntu-Package comes with "uzbl-browser" and "uzbl-tabbed", which are two frontends of uzbl that can actually be used as browsers.
The uzbl website sais:
Uzbl follows the UNIX philosophy - "Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface."
This philosophy is good and was good, and unfortunately, this philosophy is forgotten very often by now, even in the Unix-World. And especially when it comes to the Web. On the other hand, for the newb, uzbl is definitely harder to use than other browsers, you have to learn it. It is like Vi, Emacs, Mutt, the Midnight Commander, and several other tools: If you are willing to invest a bit of time to get used to it, you will probably never want anything else again. But if you are not willing to, well, you will not be lucky using it.
A major problem of the uzbl-browsers is the lack of documentation about their keybindings, but this Wiki-Entry tells most of it.
Of all the browsers I know, uzbl is the one which I think has the best philosophy so far, and it is the only alternative "unix-like" browser I know that is really usable in real-life. Will it ever become a widely-known browser - I do not know, but it is definitely possible.
Well, there are exceptions like some add-ons for Firefox which add Vi-like keybindings. And there is uzbl. Uzbl is not a browser, it is more like a framework for creating browsers and implementing several features. But the Ubuntu-Package comes with "uzbl-browser" and "uzbl-tabbed", which are two frontends of uzbl that can actually be used as browsers.
The uzbl website sais:
Uzbl follows the UNIX philosophy - "Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface."
This philosophy is good and was good, and unfortunately, this philosophy is forgotten very often by now, even in the Unix-World. And especially when it comes to the Web. On the other hand, for the newb, uzbl is definitely harder to use than other browsers, you have to learn it. It is like Vi, Emacs, Mutt, the Midnight Commander, and several other tools: If you are willing to invest a bit of time to get used to it, you will probably never want anything else again. But if you are not willing to, well, you will not be lucky using it.
A major problem of the uzbl-browsers is the lack of documentation about their keybindings, but this Wiki-Entry tells most of it.
Of all the browsers I know, uzbl is the one which I think has the best philosophy so far, and it is the only alternative "unix-like" browser I know that is really usable in real-life. Will it ever become a widely-known browser - I do not know, but it is definitely possible.
Thu, 24 Feb 2011 01:10:17 GMT
And now let's have a huge heaped spoon of sympathy for those poor scientists who cannot admit that they are doing animal experiments because of those evil animal welfare activists!
In no way can their work be considered useless, but their pitiable fate is to do these experiments for the sake of human welfare while being seen as monsters that torture animals. While they are always acting responsible with the lives of the creatures they are researching, evil animal rights activists even attacked children of the poor researchers that admitted their research activities.
If you see an animal welfare activist, always keep in mind that he might already have insulted a scientist. The public must make sure not to give those evil animal welfare activists a pulpit!
In no way can their work be considered useless, but their pitiable fate is to do these experiments for the sake of human welfare while being seen as monsters that torture animals. While they are always acting responsible with the lives of the creatures they are researching, evil animal rights activists even attacked children of the poor researchers that admitted their research activities.
{kind=link}
If you see an animal welfare activist, always keep in mind that he might already have insulted a scientist. The public must make sure not to give those evil animal welfare activists a pulpit!
Thu, 10 Feb 2011 23:30:40 GMT
Microsoft QuickBasic and its little brother QBasic was the first programming language I was writing code for. It taught me programming. Today, I rather use Lisp, and many academic people tend to not really take this language serious. Well, it lacks of some features, and has special syntax for a lot of things that would not need it (LINE, etc.). But it really has some "modern" features one might not expect.
QuickBasic has a crude form of Continuations. Well, it is not like Scheme, where you can have many of them and call them as you like. And you have to use Tricks to make them work in a modern manner. And there are a lot of limitations that certainly could be avoided. But anyway, for a language like QuickBasic, this is still amazing.
Firstly, I think in times of GWBasic and more ancient Basic-Dialects, there were no Sub- and Function-Procedures (I am not quite sure about this, clarifications are welcome), but to create subprocedures, one used GOSUB and RETURN. Though QBasic has subprocedures, these instructions are still supported, and if one does not need recursion and is willing to relinquish the modularity of subprocedures, she gets some quite flexible tools (which are - admittedly - not far above Assembler, but as many Lispers will know, sometimes less is more).
GOSUB pushes the current Instruction Pointer on the stack, and jumps to a declared line number or label. It is like GOTO, just that you can jump back. After a GOSUB, a RETURN jumps back, or - if a line number or label is supplied - to this line number or label, but in any case, it pops one instruction pointer from the stack. So RETURN and GOSUB can be used to emulate subprocedures (without local variables of course) and with them some sort of continuation. Here is an example:
DIM i, j AS DOUBLE
in:
INPUT "Number:", i
j = 1
GOSUB fact
PRINT "Fact:", j
END
fact:
IF i < 0 THEN
PRINT "Number must be greater than or equal 0!"
RETURN in
ELSEIF i = 0 THEN
RETURN
ELSE
j = j * i
i = i - 1
GOSUB fact
RETURN
END IF
There is also a CLEAR-Statement which purges the current Stack, but actually, I have not found a way to really use it so far. And of course, there is no direct possibility to just pop one element from the stack. One could use
RETURN popLabel
popLabel:
to achieve this. In the above program, one could therefore make the Stack not increase through the (tail-recursive) calls of fact.
However, it is more interesting to look at the error handling. QBasic has an instruction called ON ERROR GOSUB which a label can be passed. The program then jumps to that label, and with RESUME (not RETURN in this case - why ever) we can resume the program at some other label, and with RESUME NEXT, we can continue it.
DECLARE FUNCTION fact# (i AS DOUBLE)
DECLARE FUNCTION factinp# ()
ON ERROR GOTO handler
PRINT "Fact:", factinp
END
handler:
PRINT "Number must be greater than or equal 0!"
RESUME NEXT
DEFDBL F
FUNCTION fact (i AS DOUBLE)
IF i < 0 THEN
ERROR 5
ELSEIF i = 0 THEN
fact = 1
EXIT FUNCTION
ELSE
fact = i * fact(i - 1)
EXIT FUNCTION
END IF
END FUNCTION
FUNCTION factinp
begin:
DIM i AS DOUBLE
INPUT "Number:", i
ON LOCAL ERROR GOTO fail
factinp = fact(i)
EXIT FUNCTION
fail:
ERROR 5
' if resumed, we just ask again
RESUME begin
END FUNCTION
Oh, and this ON-Statement is even more flexible. For example, there is a predefined Timer-Interrupt-Caller, with which one could (in theory) implement a context switch and therefore some sort of preemptive multithreading (of course, this is not in the scope of the language anymore). The below example shows this. It can be closed via F4 when you run it - here you also see the On-Key functionality, which is nice.
KEY(4) ON
ON KEY(4) GOSUB ende
GOSUB 1
1 ON TIMER(1) GOSUB 2
RETURN 3
3 TIMER ON
DO: PRINT "Thread 1": LOOP
2 ON TIMER(1) GOSUB 1
RETURN 4
4 TIMER ON
DO: PRINT "Thread 2": LOOP
ende:
QuickBasic lacks of tail call optimization. There are, of course, possibilities to reduce the stack size anyway, using the STATIC statement. But this can be done with many other programming languages too. However, what can be done is to catch stack overflows - which is rather complicated using for example C - one would probably use libsigsegv for it under Unix. The following code counts to 1000 (which is of course not very useful, but easier to understand). It realizes a trampoline call to the subprocedure "test". However, "test" calls itself as long as possible, and as soon as it is not possible anymore, it uses the handling of the stack overflow to save the current argument and return, such that the trampoline call can be performed.
DECLARE SUB test (i%)
DIM SHARED context AS INTEGER
KEY(4) ON
ON KEY(4) GOSUB ende
ON ERROR GOTO exitCont
context = 0
DO: test context: LOOP
exitCont:
PRINT context
ende:
END
SUB test (i%)
ON LOCAL ERROR GOTO savecontext
IF i% < 1000 THEN
test i% + 1
ELSE
context = i%
ERROR 5
END IF
EXIT SUB
savecontext:
IF ERR = 5 THEN
ERROR 5
ELSE
context = i%
RESUME NEXT
END IF
END SUB
Besides that, it unfortunately does not have function pointers. There is a function called CALL ABSOLUTE, which can call a memory adress directly. However, then you cannot use your QuickBASIC anymore without compiling it first.
Notice that the above code samples are for QuickBASIC 7.1. For QBasic, they have to be slightly adapted, but should work anyway.
QuickBasic has a crude form of Continuations. Well, it is not like Scheme, where you can have many of them and call them as you like. And you have to use Tricks to make them work in a modern manner. And there are a lot of limitations that certainly could be avoided. But anyway, for a language like QuickBasic, this is still amazing.
Firstly, I think in times of GWBasic and more ancient Basic-Dialects, there were no Sub- and Function-Procedures (I am not quite sure about this, clarifications are welcome), but to create subprocedures, one used GOSUB and RETURN. Though QBasic has subprocedures, these instructions are still supported, and if one does not need recursion and is willing to relinquish the modularity of subprocedures, she gets some quite flexible tools (which are - admittedly - not far above Assembler, but as many Lispers will know, sometimes less is more).
GOSUB pushes the current Instruction Pointer on the stack, and jumps to a declared line number or label. It is like GOTO, just that you can jump back. After a GOSUB, a RETURN jumps back, or - if a line number or label is supplied - to this line number or label, but in any case, it pops one instruction pointer from the stack. So RETURN and GOSUB can be used to emulate subprocedures (without local variables of course) and with them some sort of continuation. Here is an example:
DIM i, j AS DOUBLE
in:
INPUT "Number:", i
j = 1
GOSUB fact
PRINT "Fact:", j
END
fact:
IF i < 0 THEN
PRINT "Number must be greater than or equal 0!"
RETURN in
ELSEIF i = 0 THEN
RETURN
ELSE
j = j * i
i = i - 1
GOSUB fact
RETURN
END IF
There is also a CLEAR-Statement which purges the current Stack, but actually, I have not found a way to really use it so far. And of course, there is no direct possibility to just pop one element from the stack. One could use
RETURN popLabel
popLabel:
to achieve this. In the above program, one could therefore make the Stack not increase through the (tail-recursive) calls of fact.
However, it is more interesting to look at the error handling. QBasic has an instruction called ON ERROR GOSUB which a label can be passed. The program then jumps to that label, and with RESUME (not RETURN in this case - why ever) we can resume the program at some other label, and with RESUME NEXT, we can continue it.
DECLARE FUNCTION fact# (i AS DOUBLE)
DECLARE FUNCTION factinp# ()
ON ERROR GOTO handler
PRINT "Fact:", factinp
END
handler:
PRINT "Number must be greater than or equal 0!"
RESUME NEXT
DEFDBL F
FUNCTION fact (i AS DOUBLE)
IF i < 0 THEN
ERROR 5
ELSEIF i = 0 THEN
fact = 1
EXIT FUNCTION
ELSE
fact = i * fact(i - 1)
EXIT FUNCTION
END IF
END FUNCTION
FUNCTION factinp
begin:
DIM i AS DOUBLE
INPUT "Number:", i
ON LOCAL ERROR GOTO fail
factinp = fact(i)
EXIT FUNCTION
fail:
ERROR 5
' if resumed, we just ask again
RESUME begin
END FUNCTION
Oh, and this ON-Statement is even more flexible. For example, there is a predefined Timer-Interrupt-Caller, with which one could (in theory) implement a context switch and therefore some sort of preemptive multithreading (of course, this is not in the scope of the language anymore). The below example shows this. It can be closed via F4 when you run it - here you also see the On-Key functionality, which is nice.
KEY(4) ON
ON KEY(4) GOSUB ende
GOSUB 1
1 ON TIMER(1) GOSUB 2
RETURN 3
3 TIMER ON
DO: PRINT "Thread 1": LOOP
2 ON TIMER(1) GOSUB 1
RETURN 4
4 TIMER ON
DO: PRINT "Thread 2": LOOP
ende:
QuickBasic lacks of tail call optimization. There are, of course, possibilities to reduce the stack size anyway, using the STATIC statement. But this can be done with many other programming languages too. However, what can be done is to catch stack overflows - which is rather complicated using for example C - one would probably use libsigsegv for it under Unix. The following code counts to 1000 (which is of course not very useful, but easier to understand). It realizes a trampoline call to the subprocedure "test". However, "test" calls itself as long as possible, and as soon as it is not possible anymore, it uses the handling of the stack overflow to save the current argument and return, such that the trampoline call can be performed.
DECLARE SUB test (i%)
DIM SHARED context AS INTEGER
KEY(4) ON
ON KEY(4) GOSUB ende
ON ERROR GOTO exitCont
context = 0
DO: test context: LOOP
exitCont:
PRINT context
ende:
END
SUB test (i%)
ON LOCAL ERROR GOTO savecontext
IF i% < 1000 THEN
test i% + 1
ELSE
context = i%
ERROR 5
END IF
EXIT SUB
savecontext:
IF ERR = 5 THEN
ERROR 5
ELSE
context = i%
RESUME NEXT
END IF
END SUB
Besides that, it unfortunately does not have function pointers. There is a function called CALL ABSOLUTE, which can call a memory adress directly. However, then you cannot use your QuickBASIC anymore without compiling it first.
Notice that the above code samples are for QuickBASIC 7.1. For QBasic, they have to be slightly adapted, but should work anyway.
Tue, 08 Feb 2011 09:53:11 GMT
What the F? So far I was really contented with my Lenovo ThinkPad. But well, yesterday I got a new UMTS-Modem, which I wanted to install - noticing that the ThinkPads' BIOS does not like it. The ThinkWiki sais
"IBM/Lenovo's reasoning for this is that the combination of MiniPCI card and the integrated antenna in the ThinkPad needs to be certified by the US FCC (Federal Communications Commission). or similar agencies in other countries."
Besides that I do not quite believe that that is the only reason for Lenovo, I do believe that there are such regulations, at least in the USA.
This is just bloody stupid. They could forbid the sale of such cards without an included antenna and a notice that only this antenna is to be used. But the way it is now is the worst for all kinds of users.
The unexpierienced user who just buys an extension to his older Laptop and tries to install it will be confused and unable to handle with it. Expierienced users will beable to get their cards work, as there are quite a lot of possible solutions, and it just makes their lifes harder. Users that really want to do anything harmful with their device, like increasing the strength of their signal, can either use one of the supported devices and replace the antenna by a stronger one.
That is why I do not like that kind of regulations: They make the life of users harder, while not really keeping anybody from breaking the law if he wants.
Same for DRM, Sim-Locks and Internet Locks. They make life harder for the users, not for the lawbreakers.
"IBM/Lenovo's reasoning for this is that the combination of MiniPCI card and the integrated antenna in the ThinkPad needs to be certified by the US FCC (Federal Communications Commission). or similar agencies in other countries."
Besides that I do not quite believe that that is the only reason for Lenovo, I do believe that there are such regulations, at least in the USA.
This is just bloody stupid. They could forbid the sale of such cards without an included antenna and a notice that only this antenna is to be used. But the way it is now is the worst for all kinds of users.
The unexpierienced user who just buys an extension to his older Laptop and tries to install it will be confused and unable to handle with it. Expierienced users will beable to get their cards work, as there are quite a lot of possible solutions, and it just makes their lifes harder. Users that really want to do anything harmful with their device, like increasing the strength of their signal, can either use one of the supported devices and replace the antenna by a stronger one.
That is why I do not like that kind of regulations: They make the life of users harder, while not really keeping anybody from breaking the law if he wants.
Same for DRM, Sim-Locks and Internet Locks. They make life harder for the users, not for the lawbreakers.
Wed, 02 Feb 2011 15:18:55 GMT
I wonder wheter any of the "modern" object systems and their reflection APIs can do this:
;; define classes a and b (defclass a () ()) (defclass b () ()) (defgeneric test (obj)) (defmethod test ((obj a)) 'a-method) (defmethod test ((obj t)) 't-method) ;; the t-method is called, since b is not subclass of a (assert (eql 't-method (test (make-instance 'b)))) ;; now we add the class a as an additional superclass (reinitialize-instance (find-class 'b) :direct-superclasses (list (find-class 'a))) ;; and now, the a-method is called, since b is subclass of a (assert (eql 'a-method (test (make-instance 'b))))
Sun, 23 Jan 2011 17:56:18 GMT
It seems like in unix-like systems, the default way of executing another process is using fork(2) and execve(2), and if you want to redirect the input and output, using dup2(2). As far as I read, fork(2) creates a virtual copy of the process image, that is, it mapps the pages of the original process in a copy-on-write mode.
Now, the man page of malloc(3) sais
By default, Linux follows an optimistic memory allocation strategy. This means that when malloc() returns non-NULL there is no guarantee that the memory really is available. This is a really bad bug. In case it turns out that the system is out of memory, one or more processes will be killed by the infamous OOM killer. In case Linux is employed under circumstances where it would be less desirable to suddenly lose some randomly picked processes, and moreover the kernel version is sufficiently recent, one can switch off this overcommitting behavior using a command like:
# echo 2 > /proc/sys/vm/overcommit_memory
This behavior seems to also affect fork(2): When forking a huge process, even though there is no need to duplicate any pages, it will not be allowed, because the kernel must not overcommit. However, I do not really like the idea of having an OOM killer that randomly kills processes if there happens to be less space then necessary. So if one writes software, normally one should have only a small process that forks. On the other hand, sometimes one just wants to execute a little external executable, which is why one probably does not want two processes per default, and fork(2), execve(2) and dup2(2) are a bad choice since they need to have about twice as much available memory as the forking process.
I have heard of this problem the first time when somebody tried to use Runtime.exec in Java, and it failed, because he turned off overcommitting, and the jvm apparently used fork(2) internally - hence, the created process is as large as the whole jvm. Googling around a bit, I found that this problem is known and will probably be changed in further jvm versions.
I wondered about the alternatives, and there seems to be an alternative, called posix_spawn(p), which executes an external command without forking.
The problem is that posix_spawn(p) is not a linux-syscall, and in theory, it could be implemented via fork(2), since POSIX specifies interfaces rather than implementations. So I tried a little test. By
# echo 0 > /proc/sys/vm/overcommit_memory
I can ensure that I have the default behaviour of Linux. The following code works:
#include <malloc.h>
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main (void) {
volatile void *bla = malloc (1024*1024*1024);
int f = fork ();
printf("Pid: %d\nFork: %d\n---\n", getpid(), f);
scanf("scanf");
}
and has an output like:
Pid: 28875
Fork: 28876
---
Pid: 28876
Fork: 0
---
Now when I turn off overcommiting by
# echo 2 > /proc/sys/vm/overcommit_memory
and run the same again, it fails:
Pid: 29014
Fork: -1
---
fork(2) returns -1, which means that it was not successful, as expected. Of course, therefore, I cannot execute an external process, because one of both processes would have to run execve(2). Now, I have written code that creates a new process using posix_spawn(p). It runs sleep(1), and waits for it. If I tried to do this using fork(2), execve(2) and dup2(2), I would run into exactly that problem. However, the following code works without overcommiting:
#include <malloc.h>
#include <unistd.h>
#include <spawn.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <string.h>
int main (void) {
volatile void *bla = malloc (1024*1024*1024);
int status;
int pid;
char* spawnedArgs[] = { "/bin/sleep", "2d", NULL };
int f = posix_spawnp(&pid, spawnedArgs[0], NULL, NULL, spawnedArgs, NULL);
printf("Pid: %d\nposix_spawn: %d\npid: %d\n---\n", getpid(), f, pid);
scanf("scanf");
wait(&status);
}
and produces an output like
Pid: 29075
posix_spawn: 0
pid: 29076
---
Nice. However, when it comes to controlling the input and output of the created process, dup2(2) is not enough. One must use posix_spawn_file_actions_t for that. The following code was created by me and Matthias Benkard, and does exactly this.
UPDATE: Removed a bug found by the commentor "dothebart", thank you!
The data structure saves actions that need to be done on the file handles. I dont want to give a deeper introduction into the functions used, they have good manpages, but I think a working example is a good starting point for understanding them anyway.
#include <spawn.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
int main(int argc, char **argv) {
int out[2];
int in[2];
int pid;
posix_spawn_file_actions_t action;
char* spawnedArgs[] = { "/bin/cat", NULL };
int status;
char r[1024];
bzero(r, 1024);
pipe(out);
pipe(in);
posix_spawn_file_actions_init(&action);
posix_spawn_file_actions_adddup2(&action, out[0], 0);
posix_spawn_file_actions_addclose(&action, out[1]);
posix_spawn_file_actions_adddup2(&action, in[1], 1);
posix_spawn_file_actions_addclose(&action, in[0]);
posix_spawnp(&pid, spawnedArgs[0], &action, NULL, spawnedArgs, NULL);
close(out[0]);
close(in[1]);
write(out[1], "Hallo!", strlen("Hallo!"));
close(out[1]);
read(in[0], r, 1024);
printf("Read data: \"%s\"\n", r);
wait(&status);
posix_spawn_file_actions_destroy(&action);
return EXIT_SUCCESS;
}
The function calls "/bin/cat", which reads from the stdin and writes to the stdout. We are taking these streams and send "Hallo!" to the input, and read the output. And in fact, its output is
Read data: "Hallo!"
Of course, if I had more data to send, this program could run into a deadlock, since the write-call would block if the buffers are full. This can be solved in the usual ways, by asynchronous I/O or by multithreading. But for this example, it is better to use this simpler method.
Now, the man page of malloc(3) sais
By default, Linux follows an optimistic memory allocation strategy. This means that when malloc() returns non-NULL there is no guarantee that the memory really is available. This is a really bad bug. In case it turns out that the system is out of memory, one or more processes will be killed by the infamous OOM killer. In case Linux is employed under circumstances where it would be less desirable to suddenly lose some randomly picked processes, and moreover the kernel version is sufficiently recent, one can switch off this overcommitting behavior using a command like:
# echo 2 > /proc/sys/vm/overcommit_memory
This behavior seems to also affect fork(2): When forking a huge process, even though there is no need to duplicate any pages, it will not be allowed, because the kernel must not overcommit. However, I do not really like the idea of having an OOM killer that randomly kills processes if there happens to be less space then necessary. So if one writes software, normally one should have only a small process that forks. On the other hand, sometimes one just wants to execute a little external executable, which is why one probably does not want two processes per default, and fork(2), execve(2) and dup2(2) are a bad choice since they need to have about twice as much available memory as the forking process.
I have heard of this problem the first time when somebody tried to use Runtime.exec in Java, and it failed, because he turned off overcommitting, and the jvm apparently used fork(2) internally - hence, the created process is as large as the whole jvm. Googling around a bit, I found that this problem is known and will probably be changed in further jvm versions.
I wondered about the alternatives, and there seems to be an alternative, called posix_spawn(p), which executes an external command without forking.
The problem is that posix_spawn(p) is not a linux-syscall, and in theory, it could be implemented via fork(2), since POSIX specifies interfaces rather than implementations. So I tried a little test. By
# echo 0 > /proc/sys/vm/overcommit_memory
I can ensure that I have the default behaviour of Linux. The following code works:
#include <malloc.h>
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main (void) {
volatile void *bla = malloc (1024*1024*1024);
int f = fork ();
printf("Pid: %d\nFork: %d\n---\n", getpid(), f);
scanf("scanf");
}
and has an output like:
Pid: 28875
Fork: 28876
---
Pid: 28876
Fork: 0
---
Now when I turn off overcommiting by
# echo 2 > /proc/sys/vm/overcommit_memory
and run the same again, it fails:
Pid: 29014
Fork: -1
---
fork(2) returns -1, which means that it was not successful, as expected. Of course, therefore, I cannot execute an external process, because one of both processes would have to run execve(2). Now, I have written code that creates a new process using posix_spawn(p). It runs sleep(1), and waits for it. If I tried to do this using fork(2), execve(2) and dup2(2), I would run into exactly that problem. However, the following code works without overcommiting:
#include <malloc.h>
#include <unistd.h>
#include <spawn.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <string.h>
int main (void) {
volatile void *bla = malloc (1024*1024*1024);
int status;
int pid;
char* spawnedArgs[] = { "/bin/sleep", "2d", NULL };
int f = posix_spawnp(&pid, spawnedArgs[0], NULL, NULL, spawnedArgs, NULL);
printf("Pid: %d\nposix_spawn: %d\npid: %d\n---\n", getpid(), f, pid);
scanf("scanf");
wait(&status);
}
and produces an output like
Pid: 29075
posix_spawn: 0
pid: 29076
---
Nice. However, when it comes to controlling the input and output of the created process, dup2(2) is not enough. One must use posix_spawn_file_actions_t for that. The following code was created by me and Matthias Benkard, and does exactly this.
UPDATE: Removed a bug found by the commentor "dothebart", thank you!
The data structure saves actions that need to be done on the file handles. I dont want to give a deeper introduction into the functions used, they have good manpages, but I think a working example is a good starting point for understanding them anyway.
#include <spawn.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
int main(int argc, char **argv) {
int out[2];
int in[2];
int pid;
posix_spawn_file_actions_t action;
char* spawnedArgs[] = { "/bin/cat", NULL };
int status;
char r[1024];
bzero(r, 1024);
pipe(out);
pipe(in);
posix_spawn_file_actions_init(&action);
posix_spawn_file_actions_adddup2(&action, out[0], 0);
posix_spawn_file_actions_addclose(&action, out[1]);
posix_spawn_file_actions_adddup2(&action, in[1], 1);
posix_spawn_file_actions_addclose(&action, in[0]);
posix_spawnp(&pid, spawnedArgs[0], &action, NULL, spawnedArgs, NULL);
close(out[0]);
close(in[1]);
write(out[1], "Hallo!", strlen("Hallo!"));
close(out[1]);
read(in[0], r, 1024);
printf("Read data: \"%s\"\n", r);
wait(&status);
posix_spawn_file_actions_destroy(&action);
return EXIT_SUCCESS;
}
The function calls "/bin/cat", which reads from the stdin and writes to the stdout. We are taking these streams and send "Hallo!" to the input, and read the output. And in fact, its output is
Read data: "Hallo!"
Of course, if I had more data to send, this program could run into a deadlock, since the write-call would block if the buffers are full. This can be solved in the usual ways, by asynchronous I/O or by multithreading. But for this example, it is better to use this simpler method.
Tue, 04 Jan 2011 23:05:13 GMT
Assuming the continuum hypothesis, there is a black-withe-coloring of the real plane  into two colors, such that on every line parallel to the x-axis, there are only countably many white points, andon every line parallel to the y-axis, there are only countably many black points. I have found this, including a proof, on Mathoverflow.
into two colors, such that on every line parallel to the x-axis, there are only countably many white points, andon every line parallel to the y-axis, there are only countably many black points. I have found this, including a proof, on Mathoverflow.
Well, something similar holds for the rational plane . In that case, there is a coloring such that on every line parallel to the x-axis we only have finitely many white points, and on every line parallel to the y-axis, we only have finitely many black points.
. In that case, there is a coloring such that on every line parallel to the x-axis we only have finitely many white points, and on every line parallel to the y-axis, we only have finitely many black points.
The proof is simple: We know there exists a bijection . Now color every point
. Now color every point  white if
white if  , and black otherwise. For every q there can only be finitely many p such that , and for every p there can only be finitely many q such that
, and black otherwise. For every q there can only be finitely many p such that , and for every p there can only be finitely many q such that  .
.
The interesting part about that is that this is a constructive result - it can actually be calculated - but still, it is highly counter-intuitive that such a coloring exists, and its rather difficult to find it when you do not know it already.
The awesomeness of Common Lisp gives a great opportunity to actually code it, using its included facilities of fractions:
(defun cantor-pair (n m)
(+ (* (+ n m) (+ n m 1) (/ 2)) m))
(defun z-to-n-0 (z)
(+ (* 2 (abs z)) (signum z)))
(defun rat-pair (q)
(cantor-pair (z-to-n-0 (numerator q)) (1+ (denominator q))))
(defun white-p (p q)
(< (rat-pair p) (rat-pair q)))
It uses Cantor's pairing function. I thought it'd be interesting to actually draw these points. Well, actually, it is not really interesting, anyway, here is the code that uses lispbuilder-sdl:
(sdl:with-init ()
(sdl:window 400 400)
(let ((zoom 100))
(flet ((draw-zoomed ()
(sdl:clear-display (sdl:color :r 0 :g 0 :b 0))
(dotimes (i 400)
(dotimes (j 400)
(when (white-p (/ i 400 zoom) (/ j 400 zoom))
(sdl:draw-pixel-* i j :color (sdl:color :r 255 :g 255 :b 255)))))
(sdl:update-display)))
(draw-zoomed)
(sdl:update-display)
(sdl:with-events ()
(:mouse-button-down-event
(:button btn)
(cond
((= btn sdl:mouse-wheel-up)
(incf zoom)
(draw-zoomed))
((= btn sdl:mouse-wheel-down)
(decf zoom)
(draw-zoomed))))
(:quit-event () t)))))
with the scroll-wheel you can change the interval that is shown (but be careful, if you scroll down 100 times, you get a division by zero, since the zoom will be 0 - as it was not that interesting I did not put that much effort into making it work). For everybody who does not want to do this, here is an image of some screenshot (I do not actually remember the zoom-factor):

It looks sort of nice when you scroll through it. The stripes are probably some boundaries of denominators.
[PS: For some reason, at the time of publishing this post, MathJax does not render the set-symbols correctly. I will probably investigate on this later. It should be clear anyway.]
Well, something similar holds for the rational plane
The proof is simple: We know there exists a bijection
The interesting part about that is that this is a constructive result - it can actually be calculated - but still, it is highly counter-intuitive that such a coloring exists, and its rather difficult to find it when you do not know it already.
The awesomeness of Common Lisp gives a great opportunity to actually code it, using its included facilities of fractions:
(defun cantor-pair (n m)
(+ (* (+ n m) (+ n m 1) (/ 2)) m))
(defun z-to-n-0 (z)
(+ (* 2 (abs z)) (signum z)))
(defun rat-pair (q)
(cantor-pair (z-to-n-0 (numerator q)) (1+ (denominator q))))
(defun white-p (p q)
(< (rat-pair p) (rat-pair q)))
It uses Cantor's pairing function. I thought it'd be interesting to actually draw these points. Well, actually, it is not really interesting, anyway, here is the code that uses lispbuilder-sdl:
(sdl:with-init ()
(sdl:window 400 400)
(let ((zoom 100))
(flet ((draw-zoomed ()
(sdl:clear-display (sdl:color :r 0 :g 0 :b 0))
(dotimes (i 400)
(dotimes (j 400)
(when (white-p (/ i 400 zoom) (/ j 400 zoom))
(sdl:draw-pixel-* i j :color (sdl:color :r 255 :g 255 :b 255)))))
(sdl:update-display)))
(draw-zoomed)
(sdl:update-display)
(sdl:with-events ()
(:mouse-button-down-event
(:button btn)
(cond
((= btn sdl:mouse-wheel-up)
(incf zoom)
(draw-zoomed))
((= btn sdl:mouse-wheel-down)
(decf zoom)
(draw-zoomed))))
(:quit-event () t)))))
with the scroll-wheel you can change the interval that is shown (but be careful, if you scroll down 100 times, you get a division by zero, since the zoom will be 0 - as it was not that interesting I did not put that much effort into making it work). For everybody who does not want to do this, here is an image of some screenshot (I do not actually remember the zoom-factor):
It looks sort of nice when you scroll through it. The stripes are probably some boundaries of denominators.
[PS: For some reason, at the time of publishing this post, MathJax does not render the set-symbols correctly. I will probably investigate on this later. It should be clear anyway.]